Indekseerimine (index)¶
Programmeerimiskeeltes tähendab indeks positsiooninumbrit, mis näitab elemendi asukohta erinevates andmestruktuurides. Kõik andmestruktuurid ei ole indekseeritavad, Pythonis saab positsiooninumbri väärtuse leida siis, kui tegemist on sõne, järjendi või ennikuga. Indeksitega toimetamine käib Pythonis kõigi indekseeritavata andmetüüpide puhul samamoodi.
Python on 0-indeksiga programmeerimiskeel. See tähendab, et andmestruktuuri esimene element asub indeksil 0.
Näiteks sõnes "PYTHON" vastavad igale tähele järgmised indeksid:
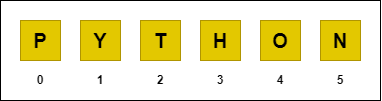
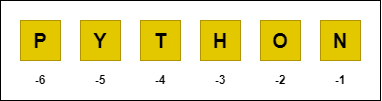
Pythonis saab kasutada ka negatiivset indekseerimist andmestruktuuri elementidele ligipääsemiseks. Negatiivseid indekseid hakatakse loendama andmestruktuuri lõpust. Oluline on tähele panna, et andmestruktuuri algusest positsioonide lugemisel on esimene element indeksiga 0, kuid negatiivse indekseerimise korral on esimeseks -1. Kui viimane element oleks ka indeksiga 0, siis oleks ebaselge, kummalt poolt loendamist alustame.
Näiteks sõnes "PYTHON" oleksid tähtedele vastavad negatiivsed indeksid järgmised:
Indeksi leidmine elemendi järgi
Kui on teada, et element eksisteerib andmestruktuuris ja on vaja leida, mis on selle indeks, on Pythonis võimalik
kasutada sisseehitatud meetodit index(), mis tagastab esimese (vasakpoolseima) indeksi, kus see element esineb. Juhul kui seda elementi
esineb mitu korda, siis teisi indekseid seda meetodit kasutades leida ei saa.
Näiteks saame nii leida, et sõnes "banana" esineb täht "b" indeksil 0 ning täht "n" esineb esimest korda indeksil 2:
print("banana".index("b")) # 0
print("banana".index("n")) # 2
Samuti saame index() meetodit kasutada järjendis - näiteks saame leida, et järjendis fruits esineb sõne "apple"
indeksil 0 ning sõne "banana" indeksil 1:
fruits = ['apple', 'banana', 'cherry']
print(fruits.index('apple')) # 0
print(fruits.index('banana')) # 1
Kui index() meetodile ette antud elementi andmestruktuurist ei leita, tõstatab Python erindi ValueError.
Elemendile indeksi järgi ligipääsemine
Teades, millisel indeksil meid huvitav element andmestruktuuris asub, saame indeksi abil selle elemendi leida. Et soovitud element leida, pannakse selle indeks nurksulgudes otse meile huvipakkuva andmestruktuuri järgi.
Näiteks sõnes "apple" asub täht "a" indeksil 0 ja täht "e" indeksil 4. Tähtede leidmiseks saab indekseid kasutada nii:
print("apple"[0]) # 'a'
print("apple"[4]) # 'e'
Samuti saab neile tähtedele ligipääsemiseks kasutada negatiivset indekseerimist:
print("apple"[-5]) # 'a'
print("apple"[-1]) # 'e'
Sarnaselt asub järjendis fruits sõne "apple" indeksil 0 ja sõne "cherry" indeksil 2 ning vajadusel saab ka järjendi
puhul kasutada negatiivset indekseerimist.
fruits = ['apple', 'banana', 'cherry']
print(fruits[0]) # 'apple'
print(fruits[2]) # ´cherry`
print(fruits[-3]) # 'apple'
print(fruits[-1]) # 'cherry'
Indeksite abil saab ligi pääseda ka väärtustele iga andmestruktuuri alamstruktuurist.
nums = [[1, 2, 3], [4, 5, 6]]
print(nums[1][2]) # 6
fruits = ['apple', 'banana', 'cherry']
print(fruits[0][4]) # 'e'
Viilutamine kasutades indekseid (slicing)
Pythonis on võimalik indeksite abil andmestruktuuri "viilutada", et sellest kiirelt sobiv alamhulk kätte saada.
Viilutamine (slicing) kasutab süntaksit [start:stop:step], kus:
starton indeks, millest alustatakse tükeldamist (sellel indeksil olev element ise on kaasa arvatud);stopon indeks, milleni viilutatakse (sellel indeksil olev element ise on välja arvatud);stepon täisarv, mis tähistab sammu suurust algusest, kui on vaja regulaarselt osa elemente vahele jätta.
Seda tehes võib vajadusel kasutada ka negatiivset indekseerimist.
Näiteks kui soovime sõnest "watermelon" indekseid kasutades võtta välja iga teise tähe, alustades lugemist teisest tähest ja lõpetades eelviimasega, saaks seda teha nii:
print("watermelon"[1:-1:2]) #aeml
Samuti järjenditega - kui soovime järjendist fruits indekseid kasutades võtta välja iga kolmanda puuvilja,
alustades lugemist teisest elemendist ning lõpetades eelviimasega, saaks seda teha nii:
fruits = [
"apple", "banana", "orange", "grape", "kiwi", "pear", "pineapple", "strawberry", "watermelon", "peach",
"mango", "cherry", "blueberry", "raspberry", "blackberry", "apricot", "plum", "lemon", "lime", "pomegranate"]
print(fruits[1:-1:3]) # ['banana', 'kiwi', 'strawberry', 'mango', 'raspberry', 'plum']
Kui jätta välja start, siis Python eeldab, et soovite alustada andmestruktuuri algusest:
language = 'Python'
print(language[:4]) # 'Pyth'
fruits = ['apple', 'banana', 'cherry']
print(fruits[:2]) # ['apple', 'banana']
Kui jätta välja stop, siis Python eeldab, et soovite valida kõik elemendid andmestruktuuri lõpuni:
language = 'Python'
print(language[1:]) # 'ython'
fruits = ['apple', 'banana', 'cherry']
print(fruits[1:]) # ['banana', 'cherry']
Kui jätta välja step, siis valitakse kõik elemendid vahemikus, mis start ja stop indeksitega täpsustatud on:
print("watermelon"[5:10]) # melon
fruits = ["apple", "banana", "orange", "grape", "kiwi", "pear", "pineapple",
"strawberry", "watermelon", "peach"]
print(fruits[3:8]) # ['grape', 'kiwi', 'pear', 'pineapple', 'strawberry']
Vaikimisi on step väärtuseks 1, -1 võimaldab andmestruktuuri itereerimist alustada selle lõpust.
Kui step lisamata jätta, saab ka kooloni kirjapildist ära jätta (nagu ka just olnud näites), kuid kui jätta
ära kas start või stop indeks, siis peab koolon kindlasti alles jääma.
Rohkem näiteid sõne viilutamist võid leida Pydoci peatükist Sõne viilutamine
Rohkem näiteid järjendi viilutamisest võid leida Pydoci peatükist Järjendi viilutamine kolme argumendiga